I previously explained how to use JavaScript to extract all URLs from your website's sitemap. Today, I want to build on top of this and re-use the same browser functions to extract the <title> and <meta name="description"> texts from the pages behind all of these URLs.
My motivation for doing this is to programmatically check the length of my pages' titles and descriptions. I have been told that titles should be no more than 70 characters and descriptions should be no more than 160 characters for optimal SEO results. Therefore, this project aims to generate a list of page URLs from my /sitemap.xml that violate these two rules. Furthermore, pages with missing titles or descriptions should also be included in the output.
As a starting point, we will use the async function that we developed before to fetch, parse, and query your website's /sitemap.xml file:
async function extractPageURLsFromSitemapXML() {
let rawXMLString = await fetch("/sitemap.xml").then((response) => response.text());
let parsedDocument = (new DOMParser()).parseFromString(rawXMLString, "application/xml");
let locElements = parsedDocument.querySelectorAll("loc");
return locElements.values().map((e) => e.textContent.trim()).toArray();
}
This function returns the list of page URLs that we will be working with, for each one, performing the following steps:
- Fetch the page from the server.
- Parse the HTML
Stringinto a data structure to work with. - Query the parsed HTML to get the page's title and description.
Finally, once we have a function to retrieve the metadata from a page, we will iterate over all pages and select the ones that do not follow the SEO rules above to obtain the final result.
Fetching the page
As before, to fetch the /sitemap.xml, we use the asynchronous fetch() function to download the page from the server. We must await the Promise object returned by fetch() to get the Response object to which the Promise resolves.
let response = await fetch(pageURL);
let rawHTMLString = await response.text();
Next, we use the text() function of the Response object to get the HTTP response body as a simple String. We have to await this function call, too, because it also returns a Promise, which resolves to the String we are looking for.
Parsing the HTML String
Also, the parsing of the raw String is similar but not the same as that of sitemap.xml. We can still use the built-in DOMParser, but we have to use the mime type text/html. The mime type controls the type of the return value of the parser. With application/xml, you get an instance XMLDocument (i.e., parsedDocument instance of XMLDocument === true), but it would not be correct in this context. Also, generally speaking, HTML documents are not valid XML documents (with the now-abandoned XHTML standard being the exception).
let parsedDocument = (new DOMParser()).parseFromString(rawHTMLString, "text/html");
Instead, we have to use the correct mime type, text/html, which makes the parsed return an instance of HTMLDocument (i.e., parsed document instance of HTMLDocument === true).
Retrieving the title and description
Now, things get more interesting. Previously, we used querySelectorAll(), which takes a CSS selector as a parameter and returns a NodeList of elements matching the given selector. This is more than we need to extract the title and description because valid pages only ever have a single title and description. Therefore, we can use querySelector(), the smaller sibling of querySelectorAll(), which also takes a CSS selector as its sole parameter. However, it returns only the first matching element. If there is no such element, then it returns null.
let title = null;
let titleElement = parsedDocument.querySelector("head > title");
if (titleElement !== null) { title = titleElement.textContent; }
Once we have an Element representing the page's <title> element, we can use the textContent property to access its text. Lastly, I'm using trim() to remove any leading or trailing whitespace.
For the description, we can use mostly the same code. We need a different CSS selector, though, and we have to extract the text in a different way because <meta> tags have no text content but keep their payload in a content attribute.
let description = null;
let descriptionElement = parsedDocument.querySelector("head > meta[name=description][content]");
if (descriptionElement !== null) { description = descriptionElement.getAttribute("content"); }
To accomplish this, we can use the getAttribute() method of the Element object.
Putting everything together
At this point, we have everything we need to write a function to extract the title and description from a given page URL.
async function extractPageTitleAndDescription(pageURL) {
let title = null, description = null;
let response = await fetch(pageURL);
let rawHTMLString = await response.text();
let parsedDocument = (new DOMParser()).parseFromString(rawHTMLString, "text/html");
let titleElement = parsedDocument.querySelector("head > title");
if (titleElement !== null) { title = titleElement.textContent; }
let descriptionElement = parsedDocument.querySelector("head > meta[name=description][content]");
if (descriptionElement !== null) { description = descriptionElement.getAttribute("content"); }
return { title, description };
}
To call this function for all page URLs extracted from /sitemap.xml, we can use a simple loop:
const pagesWithMeta = {};
for (const pageURL of await extractPageURLsFromSitemapXML()) {
pagesWithMeta[pageURL] = await extractPageTitleAndDescription(pageURL);
}
console.table(pagesWithMeta);
Note that we have to await our own functions because they are both async — they have to be because they use the browser's asynchronous functionality. In any case, here is the output of all pages with the respective titles and descriptions:
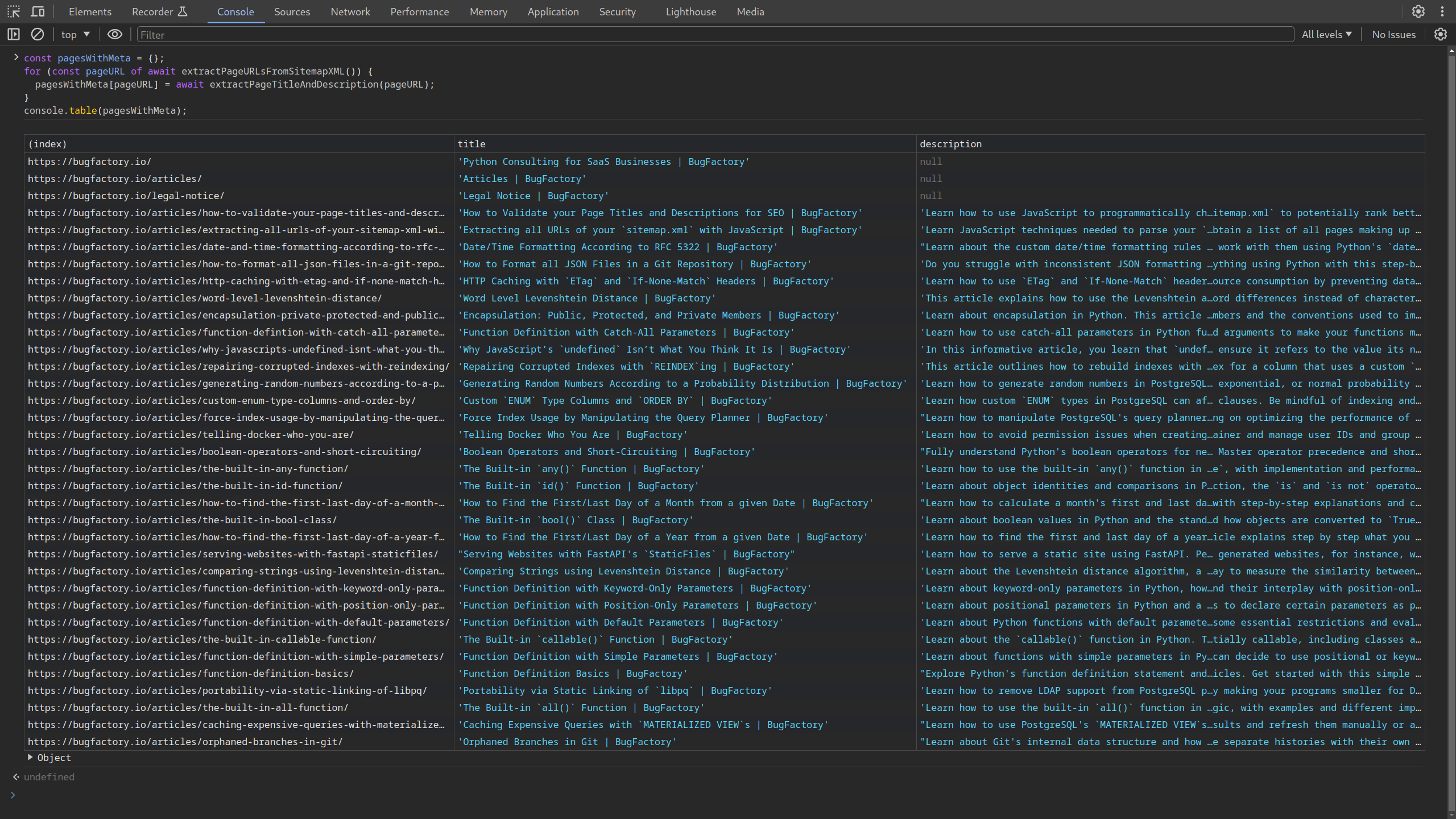
List of pages, extracted from the /sitemap.xml of bugfactory.io, together with titles and descriptions.
Checking the SEO rules
Finally, we can use the same loop again to iterate over all pages and check whether each satisfies our SEO rules. If it doesn't, we append the page to the pagesWithErrors object. Otherwise, we ignore it and do nothing.
const pagesWithErrors = {};
for (const pageURL of await extractPageURLsFromSitemapXML()) {
const { title, description } = await extractPageTitleAndDescription(pageURL);
const errors = [];
if (title === null) { errors.push('title missing'); }
else if (title.length > 70) { errors.push(`title too long ${title.length}`); }
if (description === null) { errors.push('description missing'); }
else if (description.length > 160) { errors.push(`description too long ${description.length}`); }
if (errors.length > 0) { pagesWithErrors[pageURL] = errors.join(", "); }
}
console.table(pagesWithErrors);
We are also assembling a quick description that explains what's wrong with the page. For instance, we add error messages like title too long or description missing. If you run this whole code now, you get the following output:
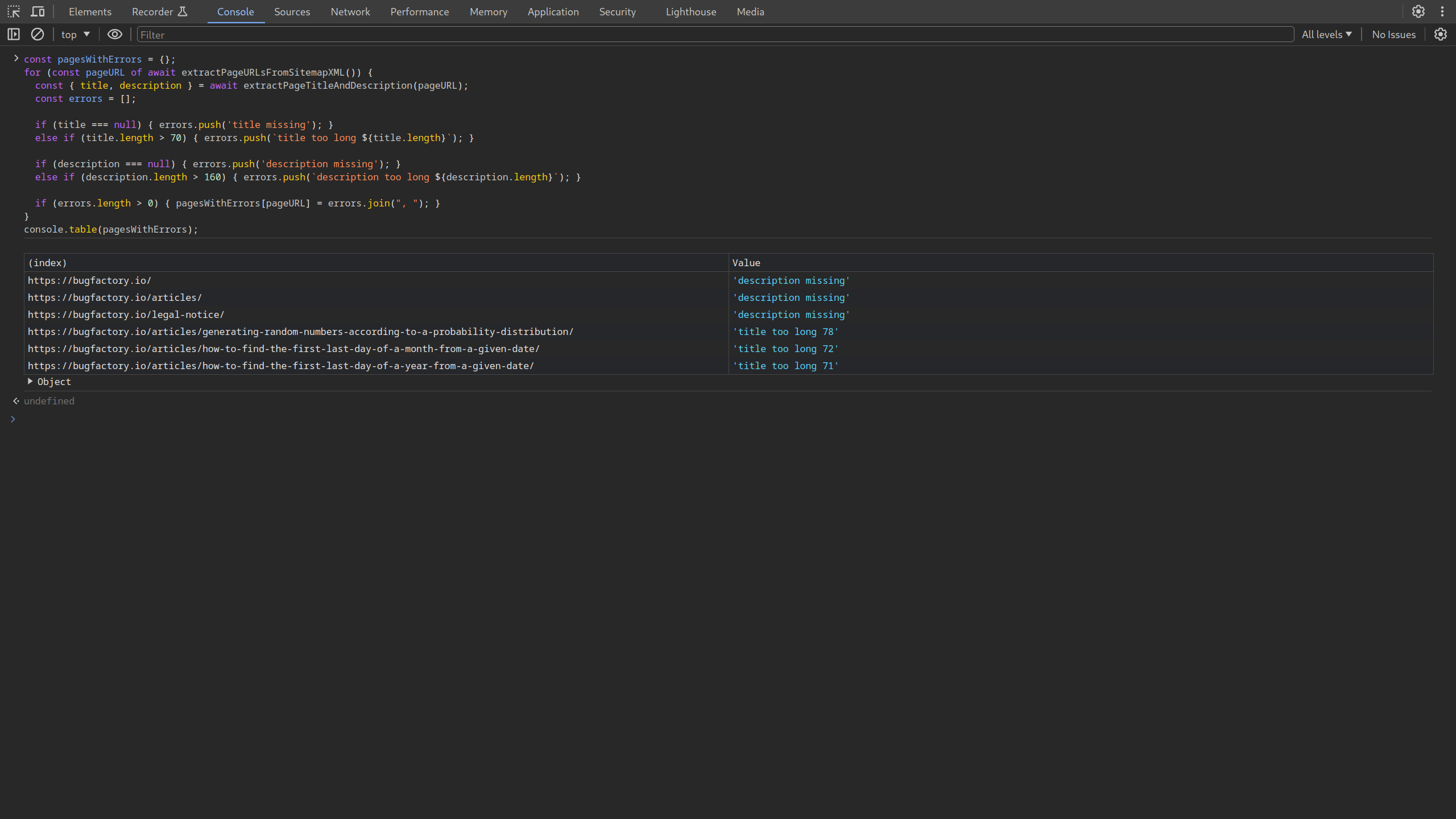
List of pages, extracted from the /sitemap.xml of bugfactory.io, that are violating the stated SEO rules.
Now I have a few pages to SEO optimize ;)
Here is the full code again for your convenience:
async function extractPageURLsFromSitemapXML() {
let rawXMLString = await fetch("/sitemap.xml").then((response) => response.text());
let parsedDocument = (new DOMParser()).parseFromString(rawXMLString, "application/xml");
let locElements = parsedDocument.querySelectorAll("loc");
return locElements.values().map((e) => e.textContent.trim()).toArray();
}
async function extractPageTitleAndDescription(pageURL) {
let title = null, description = null;
let response = await fetch(pageURL);
let rawHTMLString = await response.text();
let parsedDocument = (new DOMParser()).parseFromString(rawHTMLString, "text/html");
let titleElement = parsedDocument.querySelector("head > title");
if (titleElement !== null) { title = titleElement.textContent.trim(); }
let descriptionElement = parsedDocument.querySelector("head > meta[name=description][content]");
if (descriptionElement !== null) { description = descriptionElement.getAttribute("content").trim(); }
return { title, description };
}
const pagesWithMeta = {};
for (const pageURL of await extractPageURLsFromSitemapXML()) {
const { title, description } = await extractPageTitleAndDescription(pageURL);
pagesWithMeta[pageURL] = { title, description };
}
console.table(pagesWithMeta);
const pagesWithErrors = {};
for (const pageURL of await extractPageURLsFromSitemapXML()) {
const { title, description } = await extractPageTitleAndDescription(pageURL);
const errors = [];
if (title === null) { errors.push('title missing'); }
else if (title.length > 70) { errors.push(`title too long ${title.length}`); }
if (description === null) { errors.push('description missing'); }
else if (description.length > 160) { errors.push(`description too long ${description.length}`); }
if (errors.length > 0) { pagesWithErrors[pageURL] = errors.join(", "); }
}
console.table(pagesWithErrors);
Anyway, that's everything for today. Thank you very much for reading, and see you again next time!
